
Improving Authorship Identification with Stylometric Features
Task summary
The class competition task involves predicting whether the given two spans in TEXT columns are written by the same author or not. The task is basically binary classification, requiring a given token to be classified as follows:
0: Two spans provided in the token are written by the same author1: Two spans provided in the token are written by different authors.
The main point of the current project is to capture the stylistic metrics of each author and to incorporate these features into models to properly classify the given texts.
Exploratory data analysis
Original Dataset
The original dataset consists of English text samples with labels indicating whether the two spans in the text samples are written by the same author or not. The dataset is primarily sourced from Project Gutenberg. Each token in train.csv and test.csv has ID, TEXT, and for the training dataset, it has LABEL. The length of the texts varies in both the training dataset and text dataset. In each token, two spans are separated by a delimiter ‘[SNIPPET]’
Example of text in the dataset:
“A flat yes or no,” said Bal. “No. We can’t help them,” said Ethaniel. “ There is nothing we can do for them—but we have to try.” “Sure, I knew it before we started,” said Bal. “ It’s happened before. We take the trouble to find out what a people are like and when we can’t help them we feel bad. It’s going to be that way again.”
[SNIPPET]
“Little had been gained, little proven; the perilous thing was still there, that monstrous means of death that might come in a moment of temper or reprisal to either tribe. Alas, such weapons were not easily relinquished—and who would be first? Plainly, the way would now be slow and heavy with suspicion, but a method to abate such a threat must soon be formulated. On that Otah and Kurho were agreed! So the two great leaders agreed, and were patient, and twice more there were meetings.”
Datafiles
train.csv(1.71 MB): 1,601 rows with columnsID(dtype = int64, 0 - 1599 & 1999),TEXT(dtype = object, max length = 925),LABEL(dtype = int64,0: 1245,1: 356).test.csv(917.2 kB): 899 rows with columnsID(dtype = int64, 1600 - 2499 without 1999)TEXT(dtype = object), max_length = 1714sample_submission.csv(6.3 kB): 899 rows with columnsID(int64, 1600 to 2499 without 1999),LABEL(int64, 0 (682) or 1 (217)).
Augmented Dataset
Since the amount of provided training data is too small, I tried to augment the dataset using 6 different books that can be found in Project Gutenberg. These books are stored in the directory gutenberg. Using the script gutenberg/scripts/gutenberg_scrapping.ipynb, I created an augmented dataset that has about 33% of mismatched pairs.
gutenberg_author_pairs.csv(9.2 MB): 26,596 rows with columnsID(dtype = int64, 2000 - 28595),TEXT(dtype = object, max_length = 232),LABEL(dtype = int64,0: 10638 ,1: 15958)
After creating the augmented dataset, the total number of training data was 28,193 (0: 11883 1: 16314)
Methods
In this project, I used the pre-trained BERT tokenizer (‘bert-based-uncased’) and BERTForSequenceClassification (‘bert-based-uncased’). Without the augmented dataset, the model showed a slightly lower F1 score (0.53) and high training and validation loss (training loss : 0.53, validation loss : 0.53). Since the performance of the pre-trained BERT model was low with the original dataset, I merged the original training set and augmented the dataset to increase the number of items per label. In the original training set, there was an uneven distribution between each label (0: 1245, 1: 356). To solve this uneven distribution, augmented data had 66% of tokens that were written by the same author, and 33% of tokens that were written by different authors.
Preprocessing
Before preprocessing TEXT columns, the study first separated two spans which were separated by the delimiter [SNIPPET] . Preprocessing of each span was done by using the Python library spaCy. During the preprocessing, each word in each span was transformed into its lemma. Punctuation marks and stop words were also removed during the preprocessing.
Stylometric features
In addition to increasing the number of training data, the project utilized feature engineering to enhance the performance of the model. Based on the paper which fine-tuned the BERT model for Authorship Attribution, the project extracted three stylometric features for each span:
- average word length: The mean number of characters per word in a span
- average span length: The average number of words in a span
- punctuation frequency: The number of punctuation marks per unit of text.
This extraction was done using the Python library spaCy by creating a function called extract_stylometric_features. In the extraction process, the raw spans were used as the preprocessing removed the stop words and punctuations. The 6 stylometric features (3 for each span) were passed through a fully connected layer with a reduced dimension of 32. The final classification layer concatenates the output from BERT (768 dimensional embeddings for the [CLS] token) with 32 dimensional stylometric features. This combined representation is then passed through a classifier to predict whether the given two spans are written by the same author or not.
Training and Validation
The training data was divided into a training set and a validation set (validation size : 20%). The size of the training set was 22,557 and the size of the validation set was 5,640.
Optimizer and hyperparameters:
- optimizer: AdamW
- learning rate: 2e-5
- epochs: 3
- batch_size: 8
- max_length: 512
Validation
After each epoch, the model is evaluated on the validation dataset to track performance. The model’s predictions are compared to the true labels in the validation set to calculate metrics such as the F1 score.
Throughout the training and evaluation process, relevant metrics (loss and accuracy) are logged to WandB to visualize the model’s performance.
Results
Results of base and stylometric model with augmented data
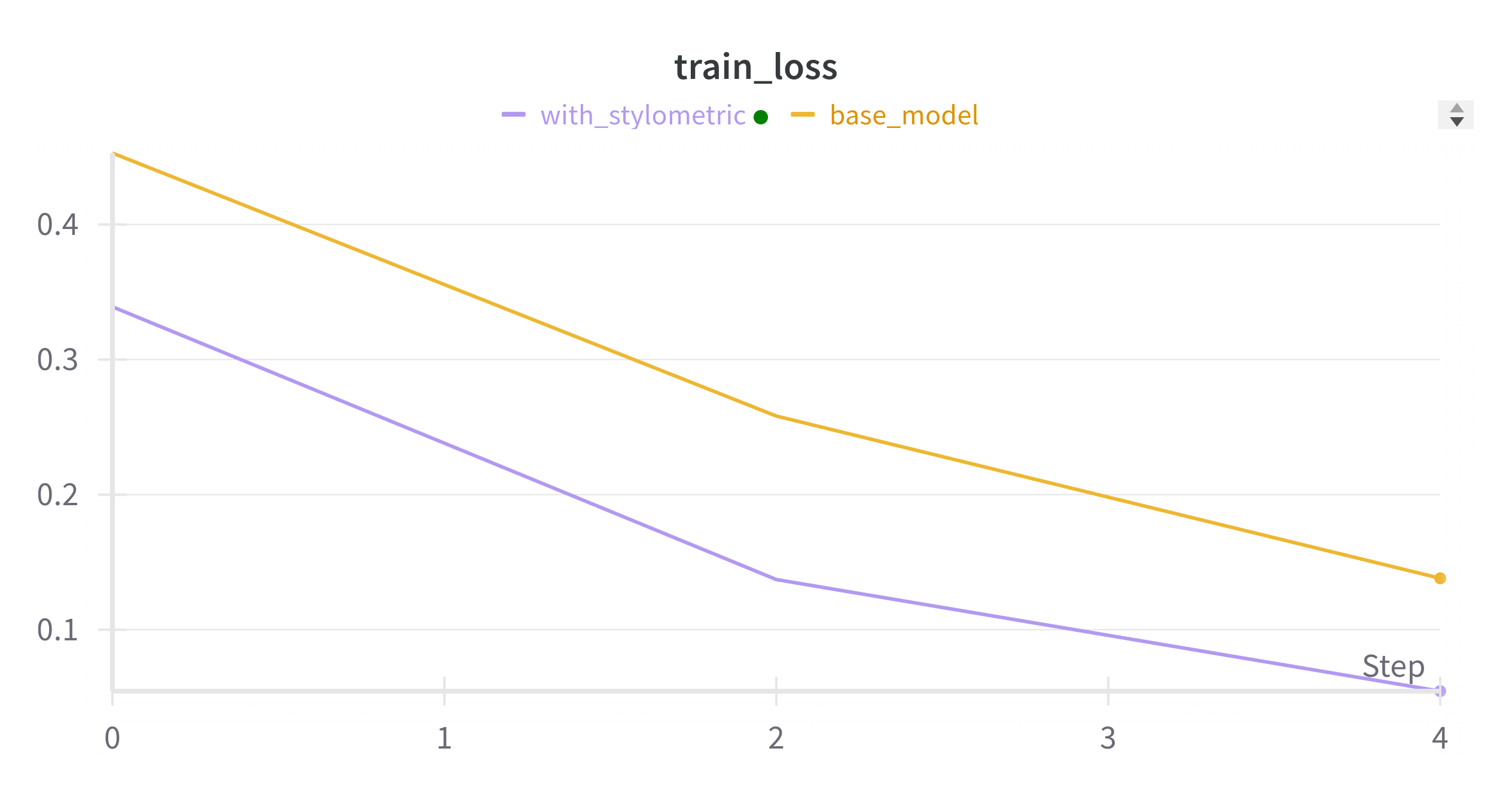
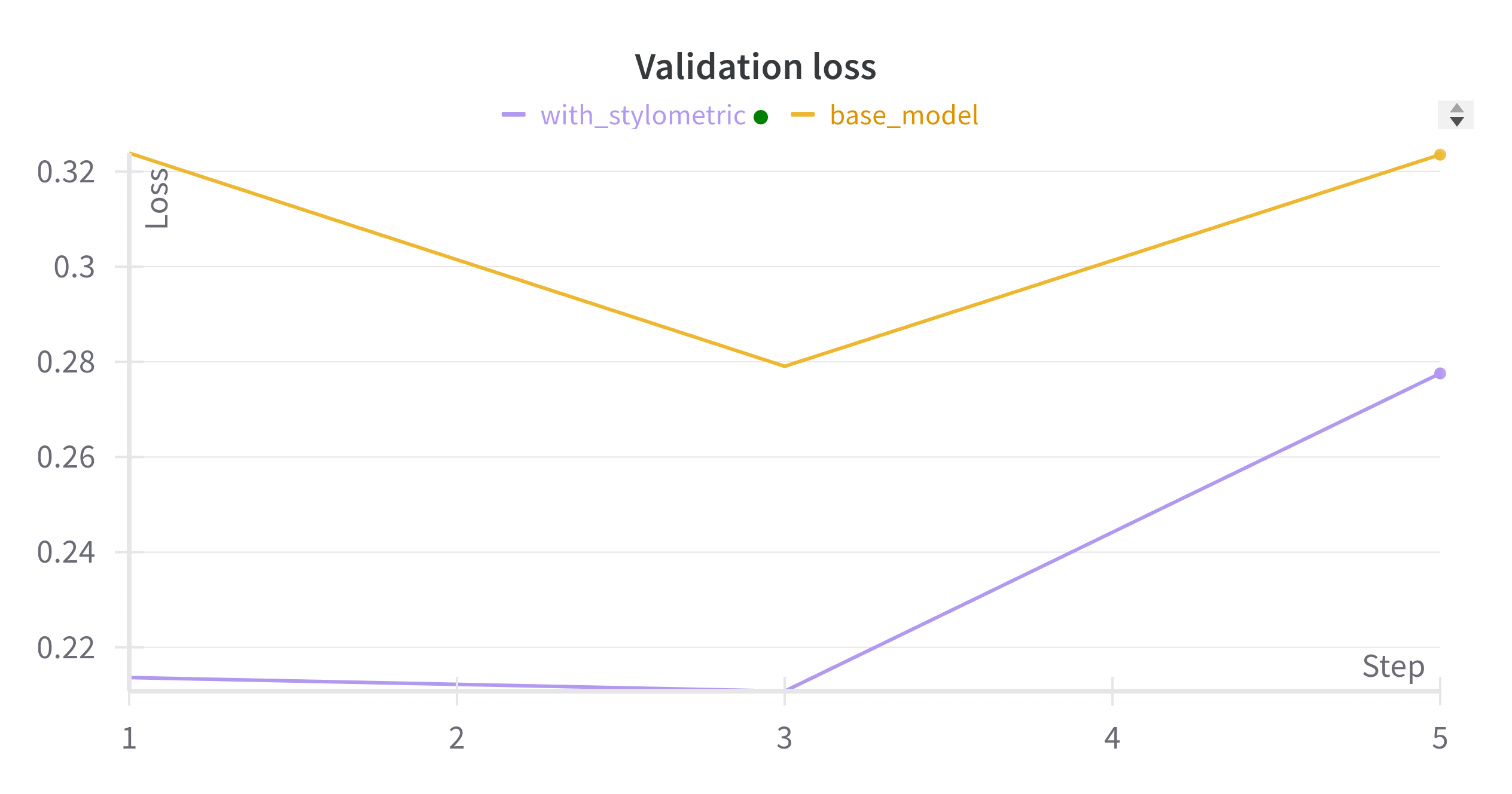
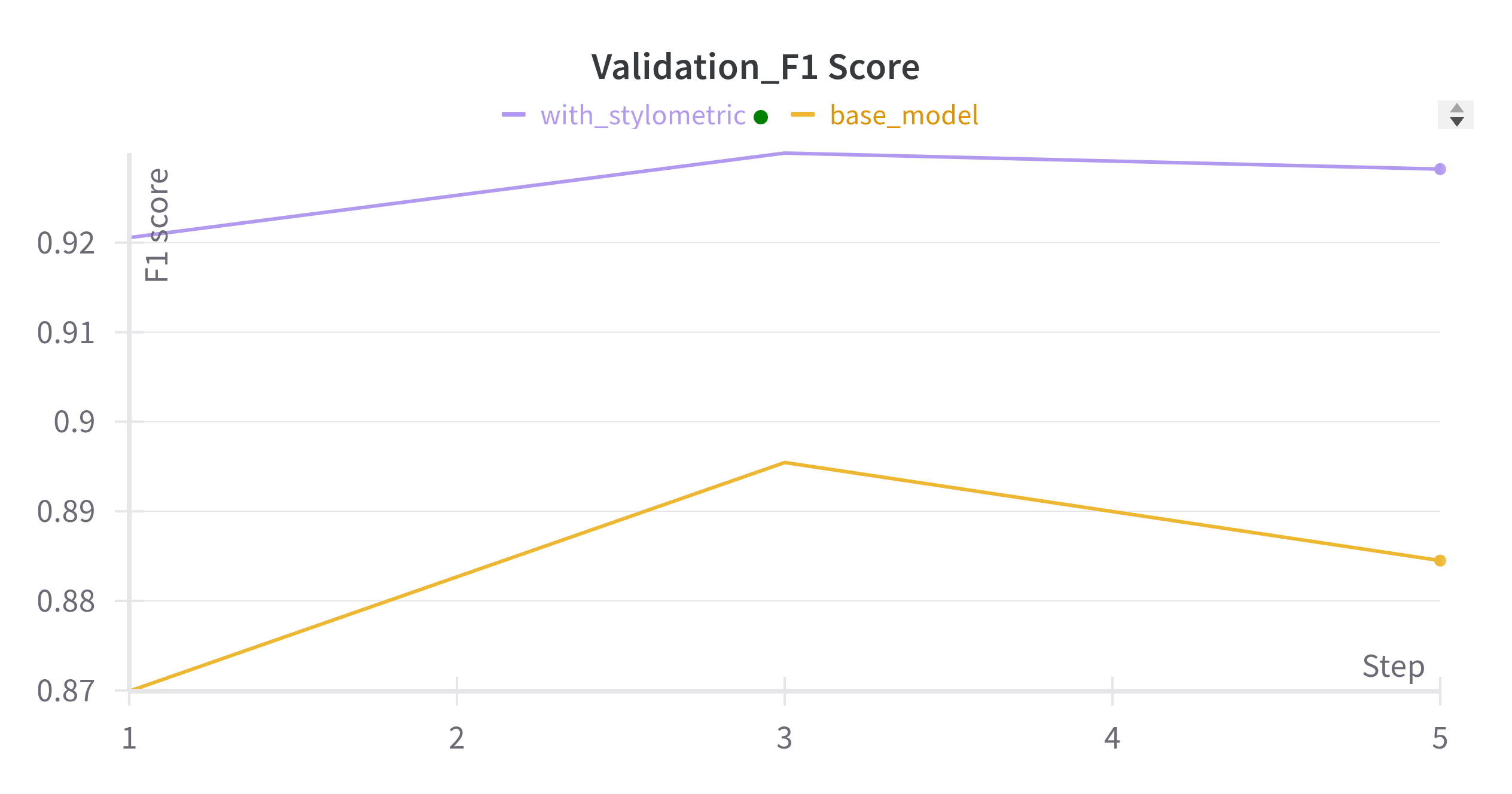
As shown in the figures, the stylometric model performed better than the base model with the augmented data.
| Model | Validation Loss | Validation F1 Score | Test F1 Score |
|---|---|---|---|
| Base Model | 0.3235 | 0.8845 | 0.63627 |
| Stylometric Model | 0.2193 | 0.9350 | 0.64467 |
The results of the testing suggest that the BERT model with the stylometric features performed better than the base BERT model.
Error analysis
During the validation phase, classification errors were collected. Among 5,640 validation tokens, the model misclassified 448 tokens. The number of false negatives in the misclassified items was 335 (74.78%), and the number of false positives in the misclassified items was 113 (25.22%) The result of the false negative and the false positive ratio suggests that the model tends to miss tokens from the positive class (two spans written by the same author) more often than incorrectly classifying tokens from the negative class (two spans written by different authors). This indicates that the model may not be sensitive enough to correctly identify the similarities between spans that are written by the same author.
In addition to analyzing the ratio of false negative and false positive, an analysis of the distribution of stylometric features such as the average word length and the average span length was conducted.
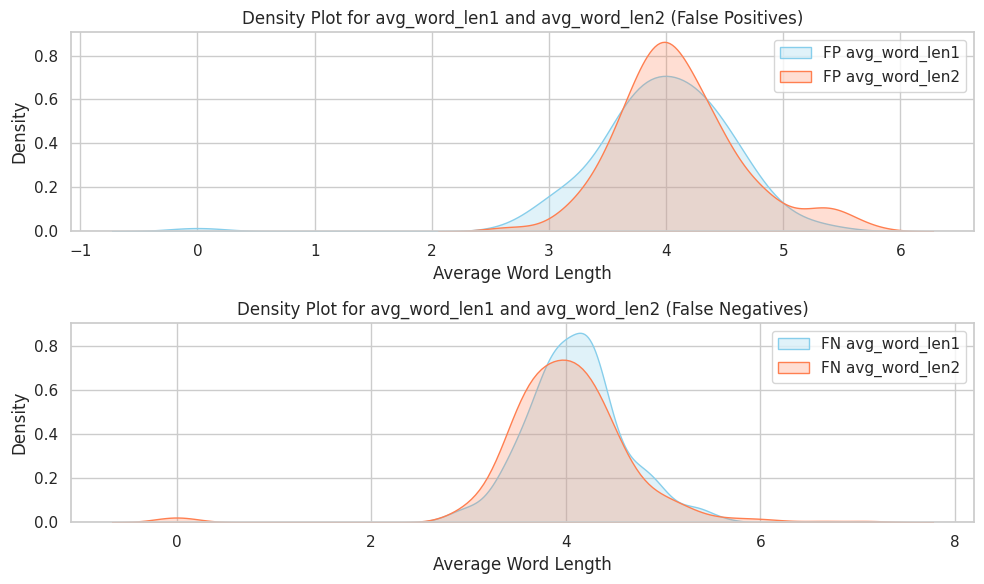
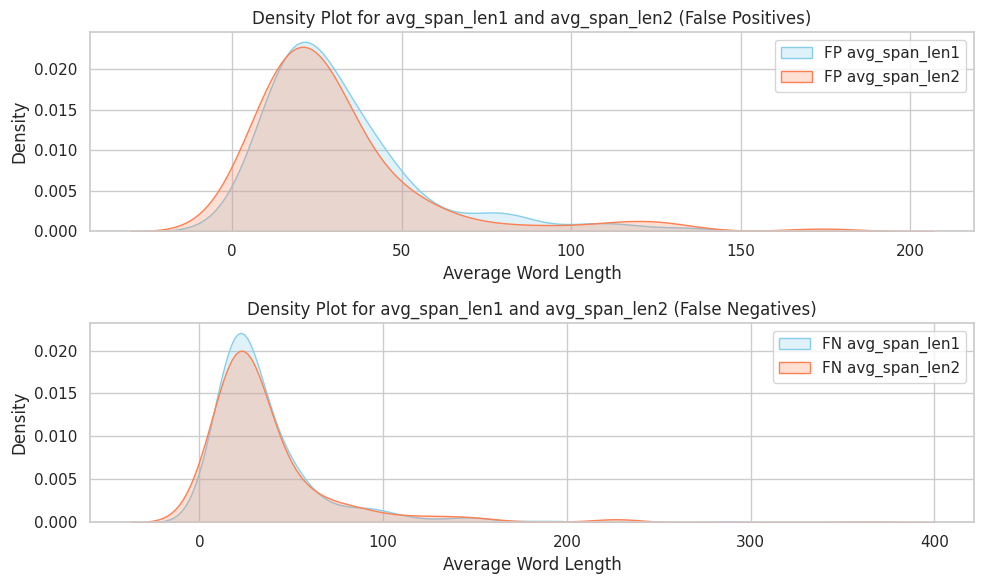
The density plots for both the average word length and average span length revealed patterns in the distribution of stylometric features among false positives (FP) and false negatives (FN). For average word length, the density plots show a similar trend. Among false positives, the distribution of avg_word_len1 and avg_word_len2 closely overlap with a peak around 4, indicating consistency in word length for spans misclassified as written by different authors. However, the false negatives showed slightly broader distributions, suggesting that the model has difficulty distinguishing between spans with little variation in word length when spans are written by the same author.
For average span length, the plots for false positive show a huge overlap between avg_span_len1 and avg_span_len2 with a sharp peak indicating that most misclassified spans in this category are relatively short. This suggests that spans classified as false positives have similar lengths regardless of whether they belong to span1 or span2. For false negatives, the distributions also overlap but have slightly more variability. This indicates that the model struggles to consistently identify spans of varying length when they are written by the same author.
Based on the analyses, both stylometric features may not differentiate between spans written by the same or different authors.
Reproducibility
Details of the methods and requirements are listed in the README.md on this Github
Future Improvements
The current project examined whether stylometric features such as average word length, average span length, and frequency of punctuation could help a model which classifies whether given two spans are written by the same author or not. The error analysis suggested that these stylometric features show overlap between each span’s distribution, indicating that these features may not increase the performance of the model significantly. As reported in the article, the model which incorporated stylometric features only showed a 2.7% increase in F1 score.