
Data collection and fine-tuning Whisper for low-resource languages
Project Summary
This internship project focuses on developing a data processing pipeline for fine-tuning the state-of-the-art (SOTA) speech recognition model [Whisper] (https://github.com/openai/whisper) for low-resource languages, including various African, Indic, and South American languages. The project involves converting and organizing audio data into the appropriate format required for Whisper and fine-tuning the model to enhance its performance. The final models are intended to be compatible with publicly available repositories such as Hugging Face and GitHub.
📁 Audio data collection and preprocessing
The initial goal of the project was to collect publicly available audio data. The primary sources included the Mozilla Common Voice corpus and various Hugging Face datasets. Given the low-resource nature of the target languages, additional datasets were sourced from platforms like Mendeley Data, which offers open-access resources for research.
Once collected, most of the audio files—especially those from Common Voice, which are typically in .mp3 format—were converted into .wav format, which is required by Whisper. Alongside the audio conversion, metadata files in .tsv format were generated. Each .tsv file included three key columns: filepath, text, and split (indicating whether the sample belongs to the training, validation, or test set).
Although an earlier version of the dataset was available in .json format, additional processing was performed to convert these into the final .tsv format, ensuring compatibility with the Whisper training pipeline. The following source code was used for file conversion from .json to .tsv.
Libraries and Tools used in the process
json: Parsing annotated audio datasets in structured format (from Common Voice)csv: Write .tsv file for Whisper-compatible metadatare: Text preprocessing (cleaning and formatting transcription)os: Accessing and iterating through file directorieswave: Used for calculating duration from raw .wav file headers
import json
import csv
import re
# Read the JSON file
input_file = "/home/kiwoong/Desktop/AIhub/src/stagecoach/data/Chichewa/updated_consolidated_speech_data.json" # Chichewa
output_file = "data/Chichewa/Chichewa.tsv" # Output TSV file path
# Open and parse the JSON file
with open(input_file, "r", encoding="utf-8") as f:
data = json.load(f)
# Write to a TSV file
with open(output_file, "w", encoding="utf-8", newline='') as tsvfile:
writer = csv.DictWriter(tsvfile, fieldnames=["filepath", "text", "split"], delimiter='\t')
writer.writeheader() # Write header
# Write rows with updated keys and modified filepath
for entry in data:
writer.writerow({
"filepath": f"data/Chichewa/{entry['FILE_PATH']}",
"text": re.sub('\n', ' ', entry["TRANSCRIPTION"]),
"split": entry["Split"]
})
print(f"Data successfully written to {output_file}")
After converting the dataset, the number of hours of each dataset was calculated. This includes calculating the number of hours in all training, validation, and test datasets in each language.
import os
import wave
def get_wav_duration(file_path):
with wave.open(file_path, 'rb') as wav_file:
num_frames = wav_file.getnframes()
frame_rate = wav_file.getframerate()
duration = num_frames / float(frame_rate)
return duration
def get_total_wav_duration(directory):
total_duration = 0
count = 0
for filename in os.listdir(directory):
if filename.endswith('.wav'):
count += 1
file_path = os.path.join(directory, filename)
total_duration += get_wav_duration(file_path)
# Convert total duration to hours
total_duration_hours = total_duration / 3600
avg_dur = total_duration/count
return total_duration_hours, avg_dur
directory = '/home/kiwoong/Desktop/AIhub/src/stagecoach/data/Yoruba/train' # Calculating number of hours in Yoruba training data
total_duration_hours, avg_dur = get_total_wav_duration(directory)
print(f"Total duration of all .wav files: {total_duration_hours} hours, avg_dur : {avg_dur}")
Results of the data collection and preprocessing
From the data collection and preprocessing steps, the following directories were created:
audiofolder with three subdirectories:train,dev,valcontaining.wavfiles with a Sampling Rate (SR) 16kHzlanguage.tsv: consists of file directories, transcription of the audio files and split
The sample output of the process is given in the following table:
| Filepath | Text | Split |
|---|---|---|
| validated_ha_wavs/common_voice_ha_29417456.wav | Habibu da Hamsatu ba su kyauta min ba. | train |
| validated_ha_wavs/common_voice_ha_26965630.wav | Ina mamakin idan an kama Ishaku. | test |
| validated_ha_wavs/common_voice_ha_26736167.wav | Kina sanye da kaya? | train |
| validated_ha_wavs/common_voice_ha_26736170.wav | An gudanar da fatin bankwana jiya sabida Mr. Jones. | train |
| validated_ha_wavs/common_voice_ha_34998133.wav | Bana jin Bitrus ne ya rubuta rahoton nan. | train |
| validated_ha_wavs/common_voice_ha_35001381.wav | Kai ɗan jami’iyyar kwamunisanci ne ta United State ko kuma ka taɓa zamowa? | train |
| validated_ha_wavs/common_voice_ha_35001430.wav | Kana tunanin da Aliko ya taimake mu? | train |
| validated_ha_wavs/common_voice_ha_35119564.wav | Dala daidai ta ke da ɗaruruwan centi. | dev |
| validated_ha_wavs/common_voice_ha_26701868.wav | Ban taba kiran shi da wawa ba. | train |
| validated_ha_wavs/common_voice_ha_26701869.wav | Ban san yadda ake kamun kifi ba. | train |
| validated_ha_wavs/common_voice_ha_26701870.wav | An kama matashin ne da hannu cikin wani rikici. | train |
| validated_ha_wavs/common_voice_ha_26701872.wav | Ina zama a wani ƙaramin ƙauye kilo mita hamsin tsakaninsu da birni. | test |
| validated_ha_wavs/common_voice_ha_26718709.wav | Ba kwa buƙatar shirya wani muhimmini jawabi. | dev |
| validated_ha_wavs/common_voice_ha_26718710.wav | Abdullahi na daya daga cikin mamallakan wannan ginin. | train |
| validated_ha_wavs/common_voice_ha_26718712.wav | Haƙiƙa bincikenka zai haifar da ɗa mai ido. | train |
| validated_ha_wavs/common_voice_ha_26718713.wav | Karen, da yaga ba zai iya iso wajena ba, ya fara haushi. | train |
| validated_ha_wavs/common_voice_ha_26699728.wav | Katin haɗe yake da kyautar. | train |
| validated_ha_wavs/common_voice_ha_26699730.wav | Ya zama ɗabi’ar matasa sanya takalmin fatarauta. | train |
These outcomes were then used in the fine-tuning process, which was a modified version of the existing stagecoach repo provided by the XRI Global team.
🎚️ Fine-tuning Whisper for low-resource languages
For my second project during my internship at XRI Global, I worked on adapting OpenAI’s Whisper model for four African and one Indic languages: Yoruba, Chichewa, Hausa, Amharic, and Urdu. My role focused on outperforming existing benchmarks that were available in Huggingface.
Language description
Yoruba
- Yoruba is a tonal language spoken by over 20 million people in Nigeria and neighboring countries. It is a Niger-Congo language. It features three distinct tones—high, mid, and low—that can change the meaning of words. The language also has a rich phonological system, including vowel length distinctions and nasalization.
- Total number of hours used in the fine-tuning: 5.13 hrs
Chichewa
- Also known as Nyanja, Chichewa is spoken in Malawi and parts of Zambia, Mozambique, and Zimbabwe. It is an agglutinative Bantu language with complex verb morphology, where affixes encode tense, aspect, mood, and subject information.
- Total number of hours used in the fine-tuning: 4.83 hrs
Hausa
- Hausa is a Chadic language widely spoken across West Africa. It features vowel harmony, a variety of consonant clusters, and frequent borrowings from Arabic and English. Its phonemic inventory includes implosives and glottalized consonants.
- Total number of hours used in the fine-tuning: 3.92 hrs
Amharic
- Amharic is the official working language of Ethiopia and belongs to the Semitic language family. It is written in the Ge’ez script and has a root-and-pattern morphology, with extensive inflectional patterns and a large set of verb forms.
- Total number of hours used in the fine-tuning: 2.30 hrs
Urdu
- Urdu is an Indo-Aryan language spoken in Pakistan and India. It uses a modified Perso-Arabic script and shares a significant lexical base with Persian and Arabic. It has a rich poetic tradition and employs elaborate honorifics and register distinctions.
- Total number of hours in the Common Voice: 82 validated hours; However, due to storage issues, 17.47 hrs were selected and used for fine-tuning.
Procedures
From the collected data, I managed to fine-tune Whisper models using both my local machine and remote GPU that was provided from the XRI Global. Since the amount of resources that can be used in my local machine was restricted, I first started with the Whisper-base model and expanded it with Whisper-large-v3-turbo for my remote GPU.
While fine-tuning Whisper model, several problems occurred.
Problem 1: Audio data too long for Whisper to process
Some of the audio files that were collected from the Common Voice and other sources exceeded the limit of the system. Therefore, I added a filter_toolong function in the training configuration to handle excessively long files from the collected audio files.
"filter_toolong": {
"module": "byLength",
"name": "ByLength",
"args": [],
"kwargs": {
"fields": ["source", "target"],
"maxLen": 180, #self.filter_len
}
}
The implementation of the filter_toolong is given in:
class FilterBase:
def __call__(self, data):
keep = []
for x in data:
if self.use(x):
keep.append(x)
return keep
from blocks.filterBlk.filterBase import FilterBase
class ByLength(FilterBase):
def __init__(self, fields, maxLen):
self.fields = fields
self.maxLen = maxLen
def use(self, sample):
for f in self.fields:
if type(sample[f]) == str:
if len(sample[f]) > self.maxLen:
return False
elif type(sample[f]).__name__ == "Tensor":
if sample[f].shape[0] > self.maxLen:
return False
return True
Problem 2: No improvement in the performance due to limited data
Libraries and Tools used in the process
pandas: Modification of the dataset and concatenating dataset for transfer learning
After filtering the long audio files using the filter_toolong, I was able to train Whisper model with different languages. While fine-tuning Whisper on Chichewa, another problem occurred. As the training data was limited, the model did not perform well on the ASR task. Therefore, a transfer learning approach was used to improve the performance of the model.
Since Chichewa is a Bantu language, I collected a subset of the Swahili dataset from the Common Voice which has an identical language family. As they are in the same language family, they have similar noun class marking (using prefixes), and agglutinative structure that verbs are built with multiple prefixes and suffixes marking tense, etc. They also share some lexical items, such as “maji” in Swahili and “madzi” in Chichewa meaning “water”. Compared to Chichewa, Swahili is a relatively high resource language that has a decent amount of audio data that can be used. After collecting the data, I utilized the preprocessing procedures and merged 30k of the audio files with the existing Chichewa dataset. Here, Swahili data was only used during the training, and Chichewa data was used for training, validation, and testing. The below code demonstrates the merging steps between the Chichewa and Swahili datasets. A total of 46.2 hours of Swahili data were added to the training dataset of the Chichewa.
import pandas as pd
ch = pd.read_csv('Chichewa.tsv', sep = '\t')
sw = pd.read_csv('swahili.tsv', sep = '\t')
sw = sw[:30000]
merged = pd.concat([ch, sw])
merged['split'].value_counts()
'''
split
Train 30267
Test 41
Dev 35
Name: count, dtype: int64
'''
While merging the Swahili data, an error occurred that the transcription (texts) exceeded the CSV field size limit. Therefore, an additional filtering was conducted by the following code:
field_limit = 131072 # Default CSV field size limit
# Filter rows without creating a new column
merged = merged[merged['text'].str.len() <= field_limit]
merged['split'].value_counts()
'''
split
Train 30264 (3 items were removed from the Swahili dataset)
Test 41
Dev 35
Name: count, dtype: int64'''
After solving these problems I was able to train the Whisper model using the following two files:
- Whisper_fintune_language (Hausa, Chichewa, Amharic, Urdu, Yoruba).py
- run.py
Since providing the source code for the entire training process was restricted, I implemented my own version of the code which follows the overall procedures that were provided in the stagecoach repo from XRI Global. The following code was used for fine-tuning Whisper on the Yoruba dataset. The result of the training was reported to [WandB] (https://wandb.ai/site/)
Libraries and Tools used in the process
transformers: Whisper model and tokenizer handlingdatasets: TSV-based dataset loading and mappingtorch: Core deep learning library; used for model optimization, tensor operations, and GPU acceleration during fine-tuning.torchaudio: Audio loading and resamplingevaluate: WER and CER computationget_linear_schedule_with_warmup: Learning rate schedulingtqdm: progress tracking (optional for batch logging)wandb: For experiment tracking (loaded but not configured)
import os
import torch
import torchaudio
from datasets import load_dataset
from transformers import (
WhisperProcessor,
WhisperForConditionalGeneration,
Seq2SeqTrainingArguments,
Seq2SeqTrainer,
DataCollatorSpeechSeq2SeqWithPadding
)
from evaluate import load
import numpy as np
from dotenv import load_dotenv
from torch.optim import Adafactor
from torch.optim.lr_scheduler import get_linear_schedule_with_warmup
from tqdm.auto import trange
import wandb
# Load environment variables
load_dotenv(os.path.expanduser('~/.env'))
# Configuration
class Config:
def __init__(self):
self.seed = 1000
self.model_name = "openai/whisper-large-v3-turbo"
self.data_source = "/home/kiwoong/Desktop/AIhub/src/stagecoach/data/Yoruba/Yoruba.tsv"
self.save_model = "WhisperTestModel"
self.save_path = f"models/forward/{self.save_model}"
self.batch_size = 2
self.grad_accum = 8
self.epochs = 20
self.learning_rate = 1e-5
self.weight_decay = 1e-3
self.warmup_steps = 5000
self.max_steps = 50000
self.filter_len = 180
self.epd = 2 # epochs per dev evaluation
self.eval_batch_size = 6
class LoadWhisper:
def __init__(self, name, device):
self.processor = WhisperProcessor.from_pretrained(name)
self.model = WhisperForConditionalGeneration.from_pretrained(name)
self.tokenizer = self.processor.tokenizer
self.model.to(device)
self.device = device
self.default_language = "yo" # Yoruba language code
def genAudio2Text(self, audio_batch, withGrad=False, temp=0, language=None):
audio_batch = [audio.squeeze().numpy() for audio in audio_batch]
inputs = self.processor(audio_batch, return_tensors="pt", sampling_rate=16000).to(self.device)
language = language or self.default_language
if language:
conditioning_tokens = [
"<|startoftranscript|>",
f"<|{language}|>",
"<|transcribe|>"
]
conditioning_input_ids = torch.tensor(
[self.processor.tokenizer.convert_tokens_to_ids(conditioning_tokens)]
).to(self.device)
batch_size = inputs.input_features.size(0)
conditioning_input_ids = conditioning_input_ids.repeat(batch_size, 1)
else:
conditioning_input_ids = None
self.model.eval() if not withGrad else self.model.train()
with torch.set_grad_enabled(withGrad):
outputs = self.model.generate(
input_features=inputs.input_features,
forced_decoder_ids=conditioning_input_ids,
max_length=448,
num_beams=4,
temperature=temp or 1.0
)
return outputs
def genHS(self, input_features):
return self.model(input_features=input_features, return_dict=True)
def genLossFromHS(self, hidden_states, labels):
return self.model(inputs_embeds=hidden_states, labels=labels).loss
class LoadLocalAudio:
def __init__(self, path, tokenizer, **kwargs):
self.path = path
self.tokenizer = tokenizer
self.extract_column = kwargs.get('extract_column', {
'audio': 'filepath',
'source': 'text',
'target': 'text',
'splits': 'split',
'src_data': 'filepath',
'tgt_data': 'text'
})
self.partitions = kwargs.get('partitions', {'train': 80, "test": 10, "dev": 10})
self.mel = kwargs.get('mel', False)
self.sample_rate = 16000
self.metrics = kwargs.get('metrics', {})
def load_dataset(self):
dataset = load_dataset('csv', data_files=self.path, delimiter='\t')
# Split dataset according to partitions
total = sum(self.partitions.values())
train_size = self.partitions['train'] / total
test_size = self.partitions['test'] / total
dataset = dataset['train'].train_test_split(test_size=1-train_size, seed=1000)
test_valid = dataset['test'].train_test_split(test_size=test_size/(1-train_size), seed=1000)
return {
'train': dataset['train'],
'dev': test_valid['train'],
'test': test_valid['test']
}
def resample_audio(self, audio_path, target_sr, mel=None):
waveform, sample_rate = torchaudio.load(audio_path)
if sample_rate != target_sr:
resampler = torchaudio.transforms.Resample(sample_rate, target_sr)
waveform = resampler(waveform)
if mel:
mel_spectrogram = torchaudio.transforms.MelSpectrogram(
sample_rate=target_sr, n_mels=80
)
waveform = mel_spectrogram(waveform)
return waveform
def prepare_dataset(self, batch):
audio = batch[self.extract_column['audio']]
text = batch[self.extract_column['text']]
# Process audio
waveform = self.resample_audio(audio, self.sample_rate, self.mel)
input_features = self.processor(
waveform.squeeze().numpy(),
sampling_rate=self.sample_rate,
return_tensors="pt"
).input_features[0]
# Process text
labels = self.tokenizer(text, return_tensors="pt").input_ids[0]
return {
"input_features": input_features,
"labels": labels
}
def evaluate(self, targets, predictions):
wer_metric = load("wer")
cer_metric = load("cer")
wer = wer_metric.compute(predictions=predictions, references=targets)
cer = cer_metric.compute(predictions=predictions, references=targets)
return {"wer": wer, "cer": cer}
class RunModelAudio:
def __init__(self, model, data, target, batchSize=6, initial=False, saveResult=False, language=None):
self.model = model
self.data = data
self.target = target
self.batchSize = batchSize
self.saveResult = saveResult
self.language = language
self.evalSet = getattr(data, target, None)
def testAudio(self):
res = {}
src, tgt, trans = [], [], []
for i in range(0, len(self.evalSet), self.batchSize):
samps = self.evalSet[i:i+self.batchSize]
tgt.extend([s["target"] for s in samps])
srcToks = [s["src_data"] for s in samps]
result = self.model.genAudio2Text(srcToks, language=self.language)
print(f'{i} Source: Audio Data\n{" "*len(str(i))} Target: {samps[0]["target"]}\n{" "*len(str(i))} fTrans: {result[0]}')
src.extend([s["source"] for s in samps])
trans.extend(result)
res[self.target] = self.data.evaluate([t.lower() for t in tgt], [tr.lower() for tr in trans])
print("RunModel: res[%s] = %s" % (self.target, res[self.target]))
if self.saveResult:
self.save_translations(src, tgt, trans, res)
return res
def save_translations(self, src, tgt, trans, res):
if not self.saveResult:
return
os.makedirs(os.path.dirname(self.saveResult), exist_ok=True)
with open(self.saveResult, 'w', newline='') as f:
writer = csv.writer(f, delimiter='\t')
writer.writerow(['Source', 'Target', 'Translation', 'WER', 'CER'])
for s, t, tr in zip(src, tgt, trans):
writer.writerow([s, t, tr, res[self.target]['wer'], res[self.target]['cer']])
class SupervisedAudio:
def __init__(self, model, batchSz, epochs, optimizer, train, grad_accum=1, dev=None, epochsPerDev=1, evalBatchSz=6, test=None, dtype="float32", savePath=None):
self.model = model
self.batchSz = batchSz
self.epochs = epochs
self.optimizer, self.scheduler = optimizer(self.model.model)
self.train = train
self.gradAccum = grad_accum
self.dev = dev
self.test = test
self.epochsPerDev = epochsPerDev
self.dtype = getattr(torch, dtype, torch.float32)
self.scaler = torch.cuda.amp.GradScaler() if dtype != "float32" else None
self.savePath = savePath
def supervisedBatch(self, x, y, doBackward=True):
try:
input_features = x.to(self.model.device, dtype=self.dtype)
labels = y['input_ids'].to(self.model.device)
attention_mask = y['attention_mask'].to(self.model.device)
self.model.train()
loss = self.model(input_features=input_features, labels=labels).loss
if doBackward:
if self.scaler:
self.scaler.scale(loss).backward()
self.scaler.step(self.optimizer)
self.scaler.update()
else:
loss.backward()
self.optimizer.step()
self.optimizer.zero_grad(set_to_none=True)
self.scheduler.step()
return loss.item()
except RuntimeError as e:
self.optimizer.zero_grad(set_to_none=True)
print("RuntimeError:", e)
return 0
def train(self):
for epoch in range(self.epochs):
total_loss = 0
num_batches = 0
for i in range(0, len(self.train), self.batchSz):
batch = self.train[i:i+self.batchSz]
x = [b["input_features"] for b in batch]
y = {"input_ids": torch.stack([b["labels"] for b in batch])}
loss = self.supervisedBatch(x, y)
total_loss += loss
num_batches += 1
if num_batches % self.gradAccum == 0:
print(f"Epoch {epoch+1}/{self.epochs}, Batch {num_batches}, Loss: {loss:.4f}")
avg_loss = total_loss / num_batches
print(f"Epoch {epoch+1}/{self.epochs}, Average Loss: {avg_loss:.4f}")
if (epoch + 1) % self.epochsPerDev == 0:
self.evaluate()
if self.savePath:
self.save_model()
def evaluate(self):
if self.dev:
dev_results = self.dev.testAudio()
print(f"Dev results: {dev_results}")
if self.test:
test_results = self.test.testAudio()
print(f"Test results: {test_results}")
def save_model(self):
if not self.savePath:
return
os.makedirs(os.path.dirname(self.savePath), exist_ok=True)
self.model.model.save_pretrained(self.savePath)
self.model.processor.save_pretrained(self.savePath)
def main():
# Set random seed
torch.manual_seed(1000)
# Initialize configuration
config = Config()
# Initialize model and processor
model_handler = LoadWhisper(config.model_name, "cuda")
processor = model_handler.processor
model = model_handler.model
# Load and prepare dataset
data_handler = LoadLocalAudio(
config.data_source,
processor.tokenizer,
extract_column={
'audio': 'filepath',
'source': 'text',
'target': 'text',
'splits': 'split',
'src_data': 'filepath',
'tgt_data': 'text'
},
partitions={'train': 80, "test": 10, "dev": 10}
)
datasets = data_handler.load_dataset()
# Prepare datasets
for split in datasets:
datasets[split] = datasets[split].map(
lambda x: data_handler.prepare_dataset(x),
remove_columns=datasets[split].column_names
)
# Initialize optimizer
optimizer = lambda model: (
Adafactor(
model.parameters(),
scale_parameter=False,
relative_step=False,
lr=config.learning_rate,
clip_threshold=1.0,
weight_decay=config.weight_decay
),
get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=config.warmup_steps,
num_training_steps=config.max_steps
)
)
# Initialize evaluation
eval_dev = RunModelAudio(model_handler, data_handler, "dev", batchSize=config.eval_batch_size)
eval_test = RunModelAudio(model_handler, data_handler, "test", batchSize=config.eval_batch_size)
# Initialize trainer
trainer = SupervisedAudio(
model_handler,
config.batch_size,
config.epochs,
optimizer,
datasets["train"],
grad_accum=config.grad_accum,
dev=eval_dev,
epochsPerDev=config.epd,
evalBatchSz=config.eval_batch_size,
test=eval_test,
savePath=config.save_path
)
# Start training
trainer.train()
if __name__ == "__main__":
main()
The sample output of the code is shown below:
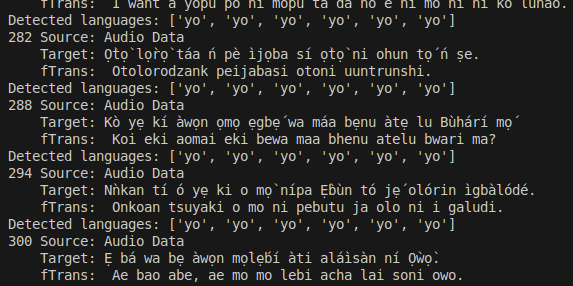
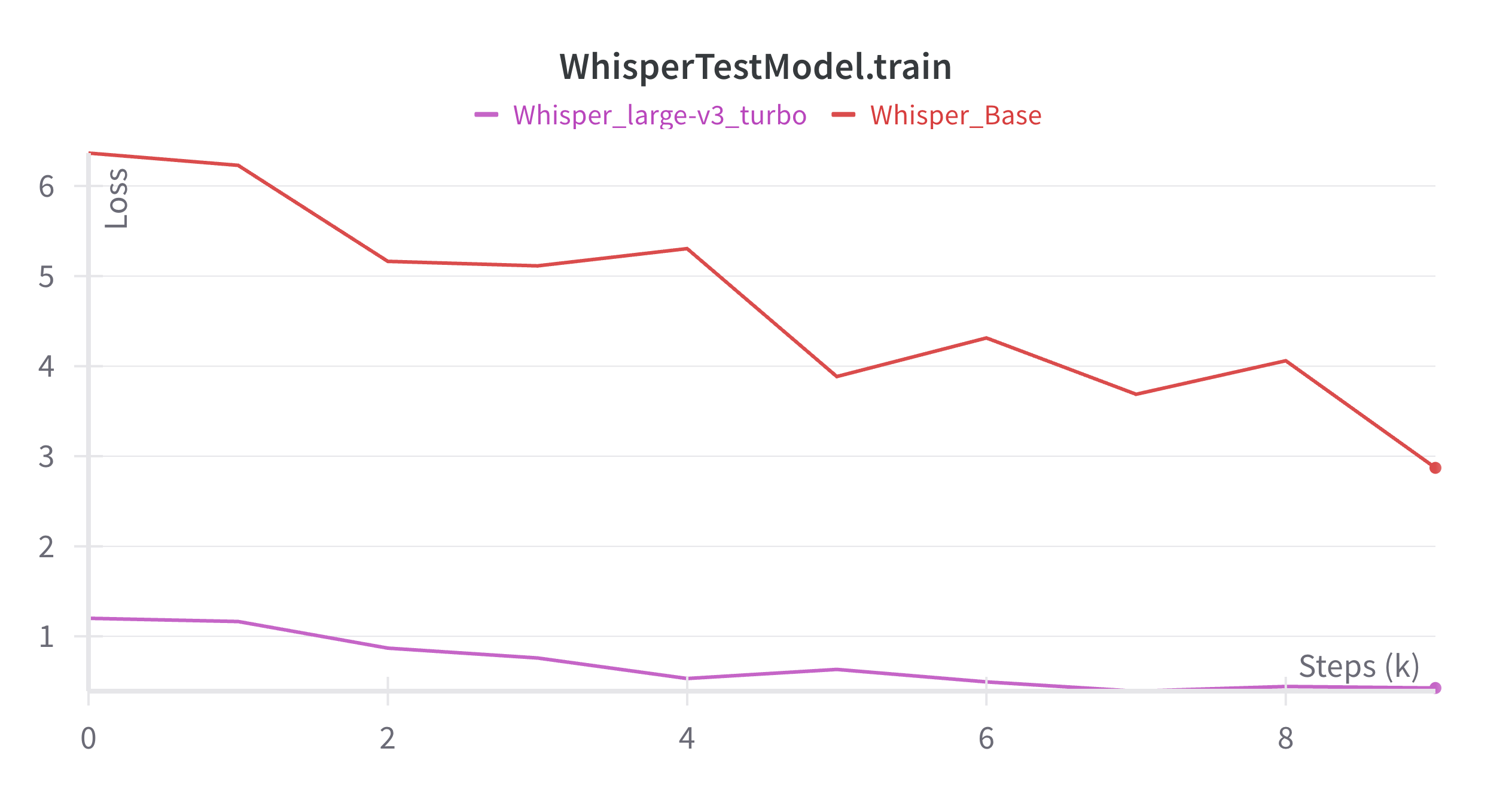
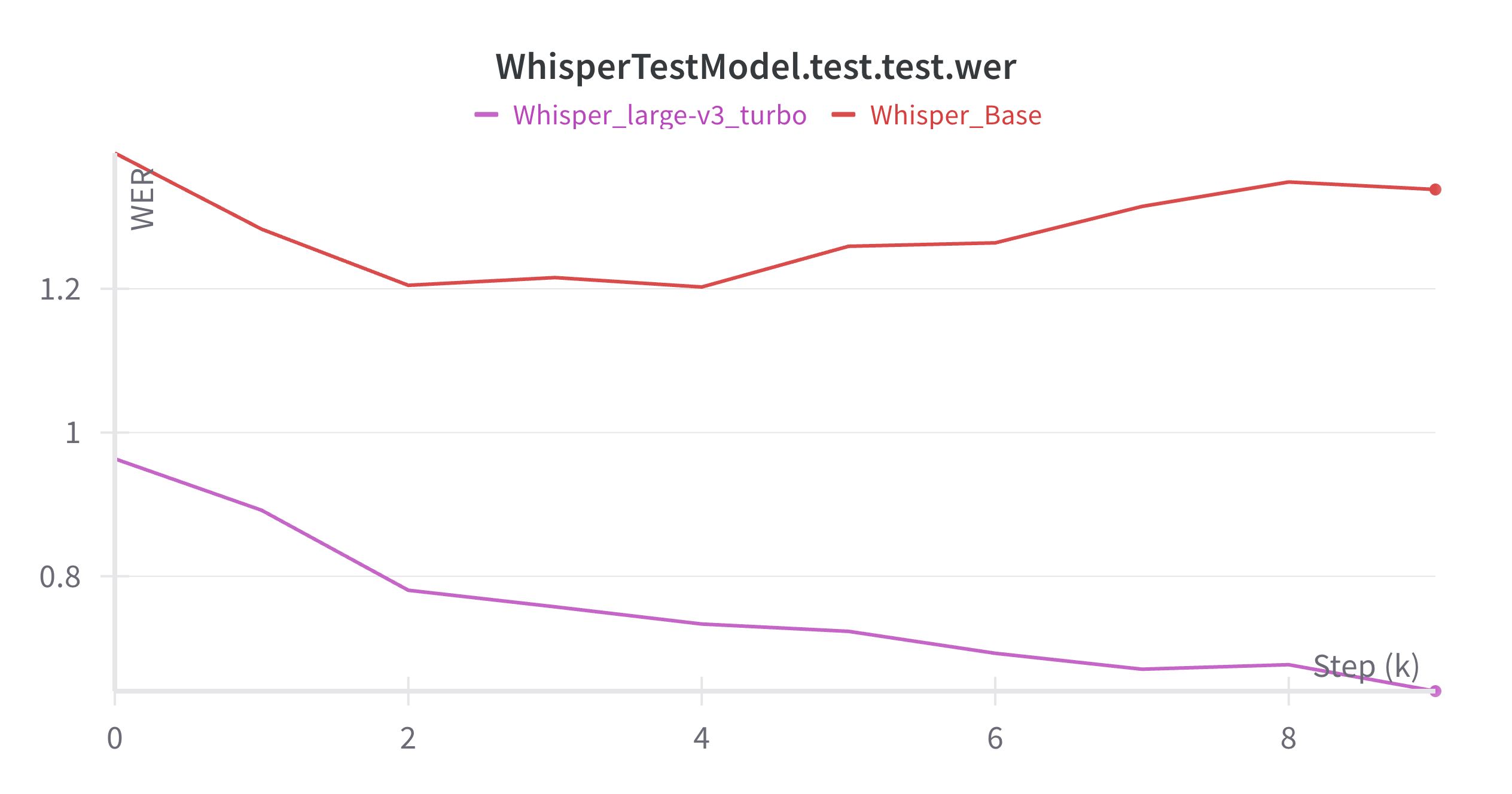
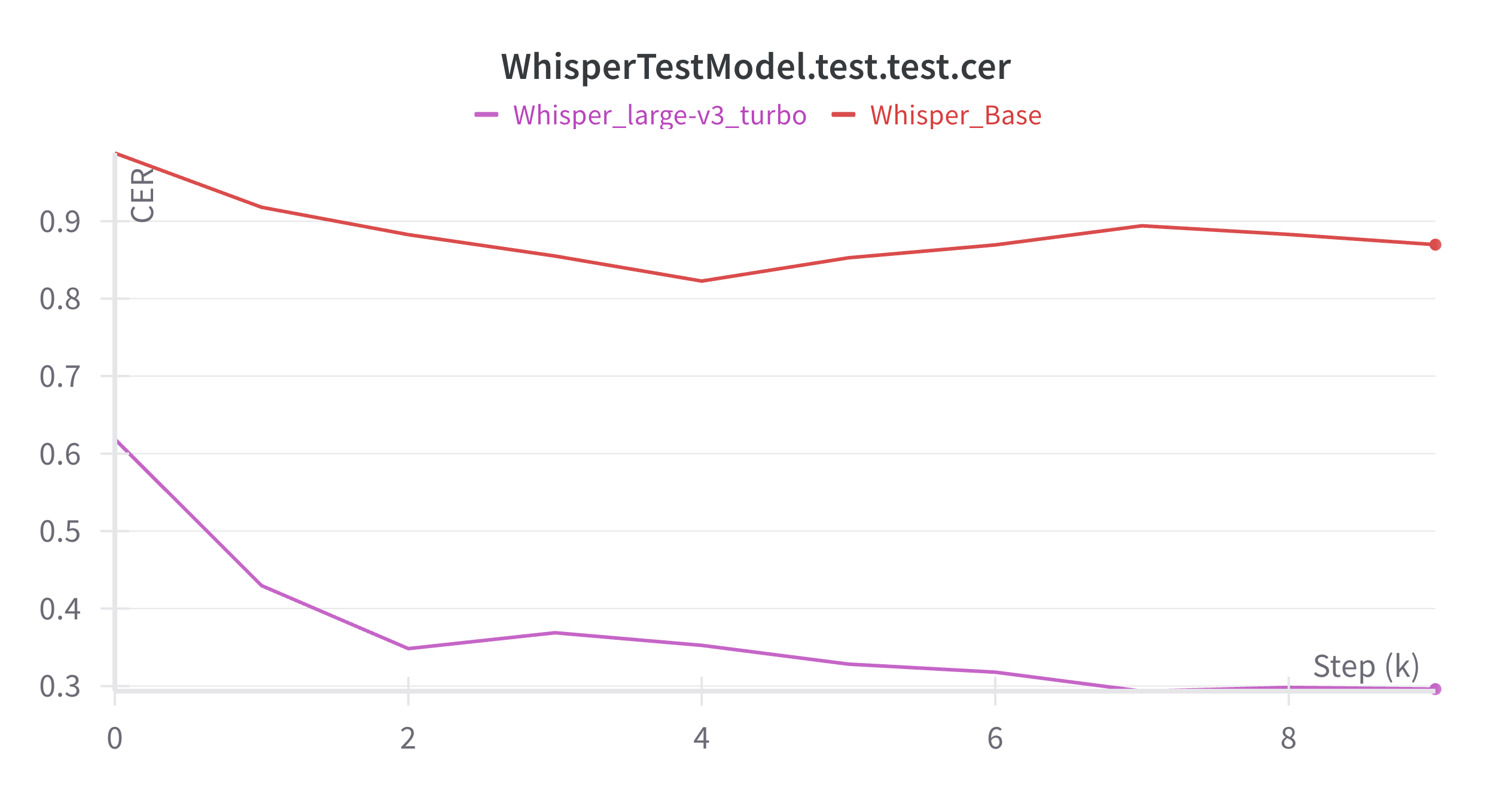
After the fine-tuning process, the result was reported to the XRI Global team by sharing the outcomes from the WandB. The figures below show the overall result of two different runs: one with the Whisper-base model and the other with the Whisper-large-turbo-v3 model.
Building and Understanding ASR Systems
This internship has been a highly rewarding journey in both technical depth and practical application. By working through the complete pipeline of Automatic Speech Recognition (ASR) model development—from raw data collection to fine-tuning and evaluation—I was able to deepen my understanding of both speech technology and multilingual modeling, particularly in the context of low-resource languages.
📁 Data Collection and Preprocessing
A major portion of the project focused on building a reliable and scalable data pipeline. I collected speech datasets from various open-source platforms such as Mozilla Common Voice and Mendeley Data. These datasets were often in inconsistent formats (e.g., .json, .mp3) and required preprocessing to meet Whisper’s input requirements. I converted audio files into .wav format (16kHz), created aligned .tsv metadata files, and wrote scripts to calculate dataset durations and ensure compatibility.
This phase gave me valuable hands-on experience with audio data handling, which includes manipulation of the data format, filtering incorrect tokens, and extracting audio information from the given directory.
🤖 Understanding and Fine-Tuning Whisper
Fine-tuning the Whisper model was the core of the internship. I worked with both whisper-base and whisper-large-v3-turbo to improve performance on ASR tasks. During this process, I encountered several challenges—including overly long audio inputs and limited data for certain languages like Chichewa. These problems were solved through:
- Custom duration filters (filter_toolong) to exclude out-of-bounds samples.
- A transfer learning approach using Swahili (a high-resource Bantu language) to supplement Chichewa’s training data.
Through these tasks, I became proficient in modifying the training loop, integrating custom dataset loaders, using Hugging Face’s transformers, and datasets, and evaluating libraries, and understanding Whisper’s architecture and decoding strategies.
📊 Experiment Tracking with WandB
The most valuable learning besides my main projects was utilizing experiment tracking with Weights & Biases (WandB). Before this internship, I was unfamiliar with how to effectively store, compare, and analyze the results and logs of my experiments. Due to the limited storage on my local machine, I often had to delete saved models, training logs, and evaluation metrics immediately after each run, which made it difficult to track progress or revisit past configurations.
WandB provided a great solution where I could automatically log training curves, evaluation metrics like WER and CER, and even model checkpoints and code versions. This not only saved disk space but also allowed me to visualize training dynamics in real time, compare different runs across languages and model sizes, and share results with the team at XRI Global seamlessly. Through this experience, I gained a solid understanding of the importance of reproducibility and experiment tracking in machine learning workflows.
Future Direction of the project
Fine-tuning the Whisper model with low-resource languages was a part of the bigger project “Language Map for low-resource languages”. The main purpose of fine-tuning the Whisper model with different languages was to update and compare the performance of the fine-tuned models with existing models that can be found in HuggingFace, Github, or publicly available websites. By collecting and updating the AI model capabilities across the world’s languages, XRI Global is expecting to bridge the digital divide and eventually establish foundational technology that supports all languages.